深度强化学习:游戏AI的革命性引擎
深度强化学习(Deep Reinforcement Learning, DRL)是人工智能领域近年来最具突破性的技术之一,它结合了深度学习的感知能力与强化学习的决策能力。在游戏领域,DRL已从实验室走向实际应用,成为驱动下一代游戏AI的核心技术。从经典的雅达利游戏到复杂的即时战略游戏《星际争霸II》,DRL智能体通过与环境持续交互、试错学习,最终达到了超越人类顶级选手的水平。这种“从零开始”的学习范式,不仅展示了AI的巨大潜力,也为游戏开发带来了全新的可能性——创建出更具适应性、挑战性和真实感的非玩家角色。
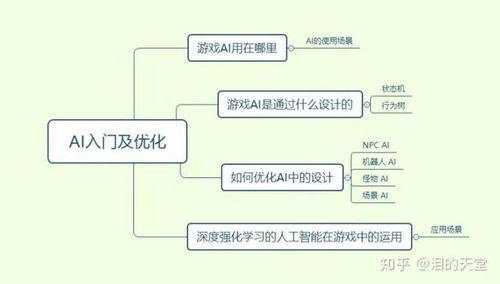
游戏AI入门:从传统方法到智能体学习
对于希望将AI引入游戏的开发者而言,理解技术演进路径至关重要。
1. 传统游戏AI技术
- 有限状态机(FSM):最基础、最广泛使用的技术,通过预定义的状态和转换规则控制NPC行为。优点是简单、直观、可预测,但缺乏灵活性和适应性。
- 行为树(Behavior Tree):通过树状结构组织决策逻辑,支持更复杂的分层和模块化设计,提高了可维护性和复用性。
- 寻路算法:如A*算法,用于解决NPC在游戏世界中的移动路径规划问题。
2. 现代学习型AI入门
从传统脚本式AI转向学习型AI,第一步是建立正确的思维框架:
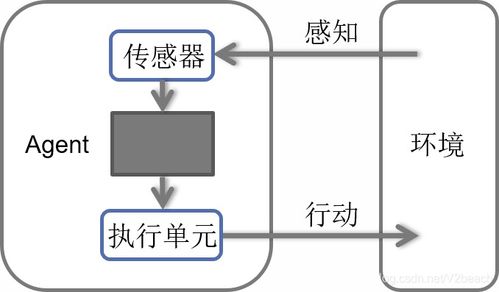
- 智能体(Agent):您控制的AI实体。
- 环境(Environment):游戏世界,智能体于此交互。
- 状态(State):环境在某一时刻的描述。
- 动作(Action):智能体可以执行的操作。
- 奖励(Reward):环境对智能体动作的反馈信号,是驱动学习的“指南针”。
入门实践建议从简单的环境开始,例如OpenAI Gym中的经典控制问题(如CartPole),或使用专为游戏AI设计的平台,如Unity的ML-Agents Toolkit或Google的Dopamine。关键是在一个定义清晰、奖励信号明确的小规模环境中,成功训练出第一个能完成基本任务的智能体。
AI优化指南:提升性能与体验的关键策略
一个成功的游戏AI不仅要“聪明”,更要高效、稳定且符合游戏设计目标。
1. 算法与模型优化
- 奖励塑形(Reward Shaping):设计中间奖励引导智能体学习,避免稀疏奖励导致的难以学习问题。这是DRL应用中最具“艺术性”的一环,需要紧密结合游戏逻辑。
- 课程学习(Curriculum Learning):让智能体从简单任务开始,逐步增加难度,如同人类的学习过程,能显著加速训练并提高最终性能。
- 集成与蒸馏:可以训练多个智能体(集成),或将大模型的知识“蒸馏”到小模型中,在保持性能的同时降低运行时计算开销。
2. 工程与实践优化
- 并行化采样:利用多个环境实例同时收集数据,极大提高数据效率,缩短训练时间。
- 模型轻量化:针对部署平台(如手机、主机)优化神经网络结构,使用量化、剪枝等技术减小模型体积和延迟。
- 人机回环(Human-in-the-loop):在训练中引入人类示范或反馈,可以更快地校正智能体的不良行为,使其更符合设计意图。
3. 设计层优化:好AI ≠ 最强AI
- 可控的挑战性:AI的水平应可动态调整,匹配不同玩家的技能,提供“心流”体验。
- 行为多样性:避免模式化,通过引入随机性或多策略学习,使AI行为难以预测,增加游戏复玩价值。
- 表现力与“欺骗”:有时需要让AI表现出拟人化的弱点或做出看似“愚蠢”但能提升玩家乐趣的决策。
人工智能基础软件开发:构建您的AI工具箱
开发游戏AI不仅需要算法知识,还需要强大的软件工程能力来构建支撑系统。
1. 核心开发框架与工具链
- 深度学习框架:PyTorch和TensorFlow是两大主流选择。PyTorch动态图特性使其在研究和原型开发中更灵活;TensorFlow则在生产部署和移动端支持上有其优势。
- 强化学习库:Stable Baselines3, Ray RLlib等高级库封装了PPO、DQN等经典算法,让开发者能更专注于问题本身而非算法实现细节。
- 游戏AI专用平台:
- Unity ML-Agents:允许在Unity引擎中直接训练智能体,无缝集成到游戏开发流程。
- Godot Engine:开源引擎,其AI相关生态也在快速发展。
2. 系统架构设计要点
- 训练与推理分离:训练系统(通常使用Python)追求灵活与高效,而部署在游戏内的推理系统(可能用C++/C#)必须追求极致的性能和稳定性。两者通过模型文件(如ONNX格式)衔接。
- 模拟环境构建:创建一个与真实游戏高度一致、但运行速度可能快数十甚至数百倍的“模拟器”用于训练,是加速迭代的关键。
- 可观测性与调试工具:开发可视化工具来监控智能体的内部状态(如价值函数、注意力分布)、决策过程和训练曲线,这对于调试复杂AI行为不可或缺。
3. 迈向生产环境
- 版本控制:不仅控制代码,也要对模型、超参数、训练数据和实验结果进行系统化管理(可使用DVC、MLflow等工具)。
- 持续集成/持续部署(CI/CD):自动化测试训练流程,确保代码更改不会破坏现有功能,并能自动将训练好的模型部署到测试环境。
- 伦理与测试:建立对AI行为的测试规范,防止出现破坏游戏平衡、利用程序漏洞(“钻空子”)或产生负面社会影响的行为。
未来展望
深度强化学习为游戏AI打开了新世界的大门,从完全自主的游戏角色到动态平衡的游戏系统,再到个性化的游戏内容生成,其应用前景广阔。技术始终是工具,成功的游戏AI永远是技术实现与游戏设计智慧的完美结合。对于开发者而言,踏上这段旅程意味着需要同时拥抱机器学习的前沿算法和扎实的软件工程实践。从一个小型实验项目开始,逐步构建起您对智能体、环境和奖励函数的直觉,最终将创造出能够真正丰富玩家体验、充满惊喜与生命力的游戏人工智能。