近期发布的《中国人工智能开源软件发展白皮书(2024)》(基于166页PPT核心内容)系统梳理了我国AI开源生态,特别是人工智能基础软件开发现状、趋势与未来路径。该白皮书为行业从业者、政策制定者及投资者提供了重要参考。以下为关键解读。
一、核心框架:从开源生态到基础软件
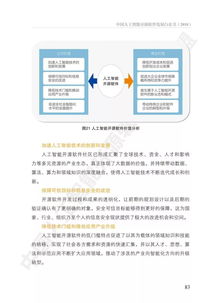
白皮书首先构建了AI开源软件的宏观图谱,将其划分为基础软件层、框架层、模型层和应用层。本次解读重点聚焦的“人工智能基础软件开发”,处于技术栈的底层与核心,主要包括:
- 计算编译器与运行时:如针对国产AI芯片的优化编译工具链。
- 分布式训练与推理系统:管理大规模集群资源,实现高效并行计算。
- 底层算子库与高性能计算库:提供芯片级性能优化的数学运算核心。
- 数据管理与版本控制工具:专门针对AI数据流水线和模型生命周期的管理软件。
二、发展现状:追赶迅速,生态初具规模
白皮书指出,中国在AI基础软件开源领域已取得显著进展:
- 自主框架崛起:以百度飞桨(PaddlePaddle)、华为MindSpore、一流科技OneFlow等为代表的深度学习框架,已在性能、易用性和特定场景(如科学计算、大模型训练)上形成特色,并积极开源,构建了从硬件适配到上层应用的初步生态。
- 硬件协同创新:为应对复杂的国际环境与国产AI芯片(如昇腾、寒武纪、海光等)的繁荣,国内团队正大力开发与之深度绑定的基础软件栈(如CANN、Cambricon BANG),旨在打通从芯片指令集到框架调用的全链路,提升整体效率。
- 社区活跃度提升:主要项目的GitHub Star数、贡献者数量、技术论文产出均呈快速增长态势,吸引了全球开发者的部分关注。
- 大模型驱动新需求:大规模预训练模型的兴起,对基础软件的分布式训练效率、超大模型存储与加载、推理部署轻量化提出了前所未有的要求,催生了相关开源子领域的创新。
三、核心挑战:技术、生态与可持续性
尽管进步明显,白皮书也深刻剖析了面临的严峻挑战:
- 技术深度与原创性:在编译器优化、调度算法、异构计算融合等最底层、最硬核的技术领域,与CUDA生态及PyTorch/TensorFlow的积累相比,仍存在差距。许多工作仍处于“跟随创新”或“适配优化”阶段。
- 全球生态主导权:国际主流生态(如PyTorch+GPU)已形成强大网络效应。国产基础软件如何吸引全球顶级开发者、学术研究者和企业用户形成“回馈-贡献”的正循环,是破局关键。
- 产业链协同难度:基础软件需要芯片厂商、框架团队、云服务商、终端应用方紧密协作。目前国内产学研用的协同效率与深度仍有提升空间,存在一定的重复建设和接口不统一问题。
- 开源可持续性与商业模式:纯粹社区驱动的项目面临资金与人力可持续压力。如何构建健康的开源商业模式(如开源核心+企业级增值服务),平衡开放与商业化,是众多项目必须解答的命题。
四、未来趋势与建议
白皮书对AI基础软件开源的未来发展做出展望并提出建议:
- 趋势一:软硬一体协同设计成为主流。未来AI基础软件的创新将更紧密地与国产AI芯片架构结合,从设计之初就考虑软硬件协同,以释放最大算力潜能。
- 趋势二:面向大模型与科学智能的专用化。基础软件将分化出更专注于千亿参数以上模型训练、AI for Science仿真计算等垂直领域的优化分支。
- 趋势三:开源与标准、安全并重。在积极开源的将更注重参与或主导国际国内标准制定,并加强AI基础软件本身的安全可信(如代码安全、供应链安全)能力建设。
建议方面,白皮书呼吁:
1. 国家层面加强战略引导与投入,在关键底层技术(如新型编译技术、并行计算模型)上设立长期攻关项目。
2. 鼓励龙头企业牵头,组建跨行业的“开源联盟”,共建共享基础软件生态,避免碎片化。
3. 完善开源人才培养与激励体系,将开源贡献纳入学术与职业评价,吸引更多人才投身底层开发。
4. 推动开源项目融入全球创新网络,积极参与国际顶级开源社区,从参与到贡献,再到主导。
###
《中国人工智能开源软件发展白皮书(2024)》的发布,标志着对中国AI开源力量的一次系统性检阅。人工智能基础软件作为“数字时代的操作系统”,其开源发展水平直接关系到我国AI产业的自主可控与创新高度。前路虽挑战重重,但通过持续的技术深耕、开放的生态共建和健康的商业模式探索,中国有望在全球AI基础软件开源格局中扮演越来越重要的角色,为世界人工智能发展贡献独特价值。